Technology
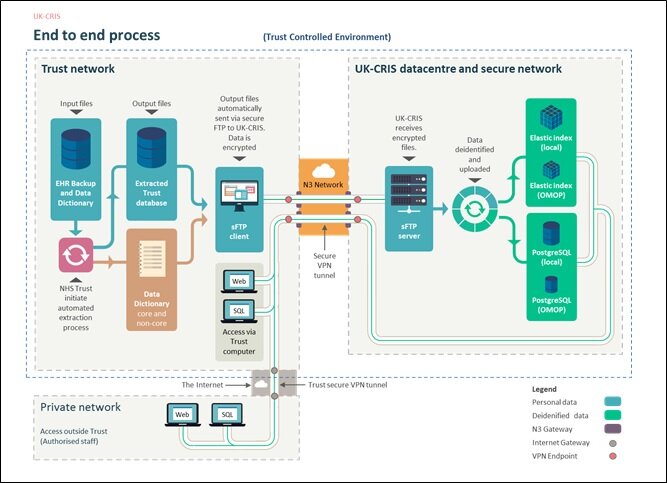
Security of patient data is paramount in the CRIS system. A series of robust technical and procedural controls are in place to secure data in transit (when its moving/being transferred) and at rest (when its being stored). Outlined below is a summary of how a CRIS database is built. This takes the form of three key stages: Extraction, Transfer and Load.
Extraction
The first stage of building a CRIS database is to extract the source data. This is carried out by the Trust by running a set of code based tasks (known as Structured Query Language (SQL) scripts). These then extract the required data and build a new database that can be used for CRIS. These also produce a data dictionary which is a key component in the CRIS build process (more on the data dictionary below).
Transfer
To enable loading of a CRIS database the data must be transferred to a specialised server to de-identify the data (remove any identifying information). Secure file transfer protocol (sFTP) is used to ensure the safe transfer of data. Firstly, the initial connection to the datacentre is guarded by a firewall and only certain computers can pass through (these have been specified by each Trust). Next the sender and receiver must correctly identify each other before a secure connection can be established. The data is then encrypted and sent over the – a private network for the NHS – to the receiving server for processing.

Load
The final stage is building the CRIS database. This involves stripping out all the information that may identify somebody and then reloading the data into three new databases. To strip out the correct information CRIS uses a data dictionary. This tells CRIS what the data is and whether it needs to be removed, masked, modified or left alone. CRIS will also remember these items. The second job of the data dictionary is to tell CRIS where it needs to look for any items it has remembered from earlier and carry out the same task to that data i.e. remove it, mask it, modify it or leave it alone. CRIS can then work through the database and apply these rules to remove the personal information relating to a patient. Once complete the new databases are built. The first database is to support the website enquiry tool, the second to support a code based query tool known as SQL and the third is a smaller database used to support federated searches. (To find out more about federation and federated searches please see the Governance page). Following the load process the source data is securely deleted from the platform. Now the deidentified CRIS database is ready and available for the NHS Trust organisations to safely query.
Want to find out more?
If you want to find out more about this process use the contact page to get in touch and a more detailed breakdown of the process can be provided. You can also get in touch with your local CRIS Network Member Trust for more information.